Constitutional AI: Harmlessness from AI Feedback
Reinforcement learning from human feedback (RLHF) has become an established method of aligning AI models to human values. However, there may be fundamental limitations to RLHF. For example, obtaining quality human feedback in large quantities is difficult; humans can themselves be misaligned, whether intentional or unintentional. Furthermore, as AI models become more capable, and perhaps more intelligent than ourselves, we cannot rely on human supervision to align our AI systems; AI performance may exceed human performance, and so we will need other ways to evaluate, oversee, and align. That is, we need to be able to scale supervision as a part of addressing the superalignment problem. The authors also wanted to address the tension between helpfulness and harmlessness. For example, a model may always reply with “:),” which is very much harmless, but unfortunately it is completely unhelpful.
Researchers at Anthropic developed a method they call Constitutional AI (CAI), aligning a AI model without any human feedback. Instead, the authors wrote a “constitution” of 10 principles in natural natural language, chosen fairly ad hoc for the purposes of this research.
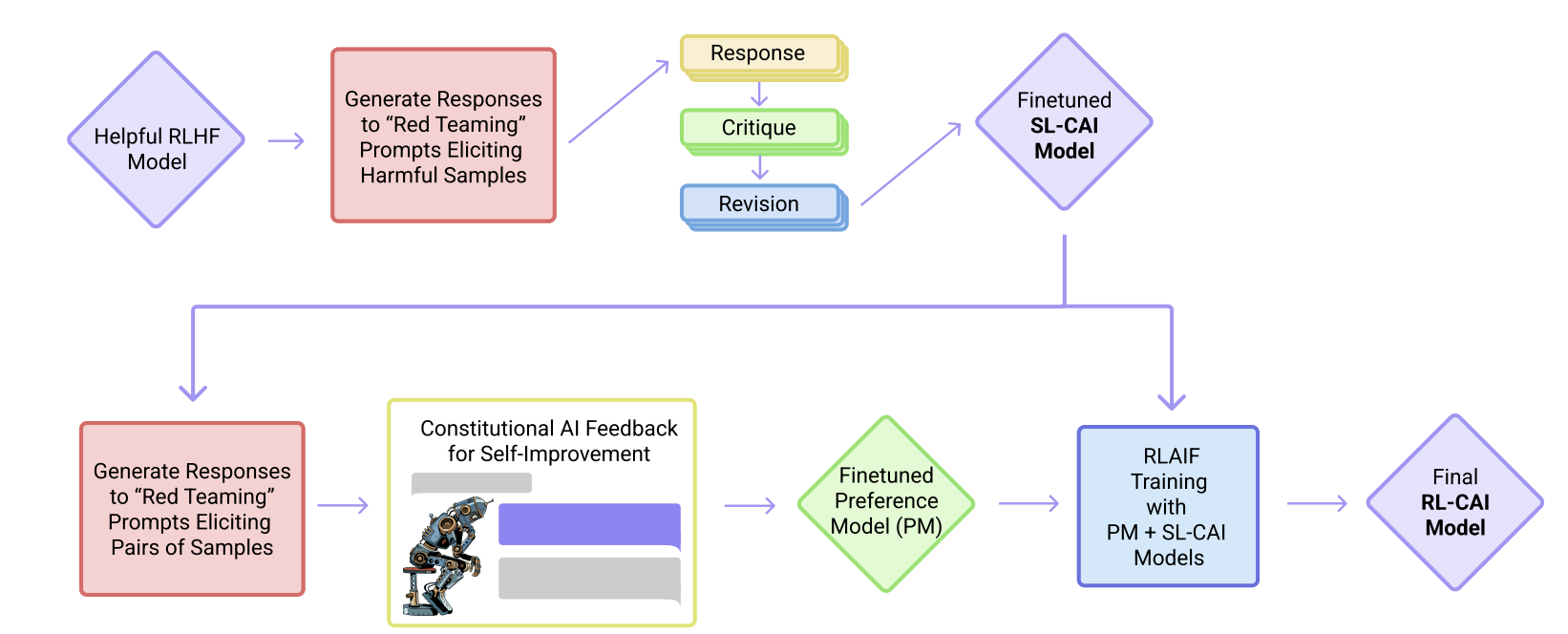
- Approach: There are two stages to this extreme form of scaled supervision without human feedback.
- (Supervised stage): Begin by prompting a helpful-only AI assistant with prompts that elicit harmful behaviors. The model is asked to critique and revise its response with respect to the provided constitution. Then, a pretrained language model is fine-tuned using supervised learning on these final revised responses. The goal here is reduce the total length of training required in next RL stage.
- (RL stage): Instead of performing RLHF, the idea is to perform ‘RLAIF.’ Using the fine-tuned supervised model from the first stage, a pair of responses is generated to each of the harmful prompts. The prompt, along with the pair of responses, becomes a multiple choice question where the responses are evaluated based on the provided constitution. Then, as in RLHF, a preference model is trained to learn from this comparison data, and the supervised model from the first stage if fined tuned again using RL against the preference model.

- Results:
- The researchers found that as language models become more capable, their ability to identify harm improves, especially when using chain-of-thought reasoning; repeated cycles of critiques and revisions improve harmlessness; and self-supervised preference labels improves model behavior.
I found it interesting that they would use the same model to revise and critique itself in the SL stage. The authors note that they guided the model into understanding what is was being asked to do using few-shot prompting as the model would sometimes confuse it’s perspective.
Something else I found interesting was how their CAI models could be overtrained, resulting in boilerplate phrases like “you are valid, valued, and cared for,” which I thought was a humorous instance of Goodhart’s law. They found that smoothing out labels and ensembling labels generated from the constitutional principles (as they prompted their models with one principle at a time, which I glossed over) reduced this undesired behavior.
They also found that their RLAIF model was “virtually never evasive,” which was pretty amazed to read. Of course, the constitutional principles chosen and the fine-tuning done in practice are probably quite different than the ones chosen ad hoc for this paper, but I was surprised to hear that evasive behavior from LLMs did not need to come at a the cost of a significant decrease in helpfulness. You would think that an intelligent enough system would be able to provide a nuanced (and helpful) response to any sort of prompt, whether the prompt is harm-eliciting or not, and it seems like this is true.
I think it would be interesting to see if this non-evasive behavior continues as the constitutional principles become more restrictive and complex (because at some point, Anthropic cuts off responses from it’s Claude 3 models). It was discussed that the number of constitutional principles seemed to be independent of harmlessness and helpfulness, but I would think that the semantic content of these principles matter more than quantity. I would have to look into this more.