How it Started (the idea)
This project began from a desire to meld reinforcement learning with image manipulation. Convolutional neural networks (CNNs) can perform position-invariant classification; that is, a CNN can identify a flower in an image no matter where the flower is in an image.
But what if we wanted to perform a different sort of something-invariant classification? For example, classification invariant under corruption, scrambling, etc. We would like to be able to extract features from an image under variations so that we are still able to perform classification. A related area of research is called dynamic feature selection or active feature acquisition.
How it Went (the project)
We narrowed the scope of our project to a simpler problem that I thought would be educationally valuable yet fun.
We developed an algorithm employing deep reinforcement learning to perform reassembly on scrambled jigsaw puzzles of the MNIST dataset. Here’s an example of one of those puzzles:
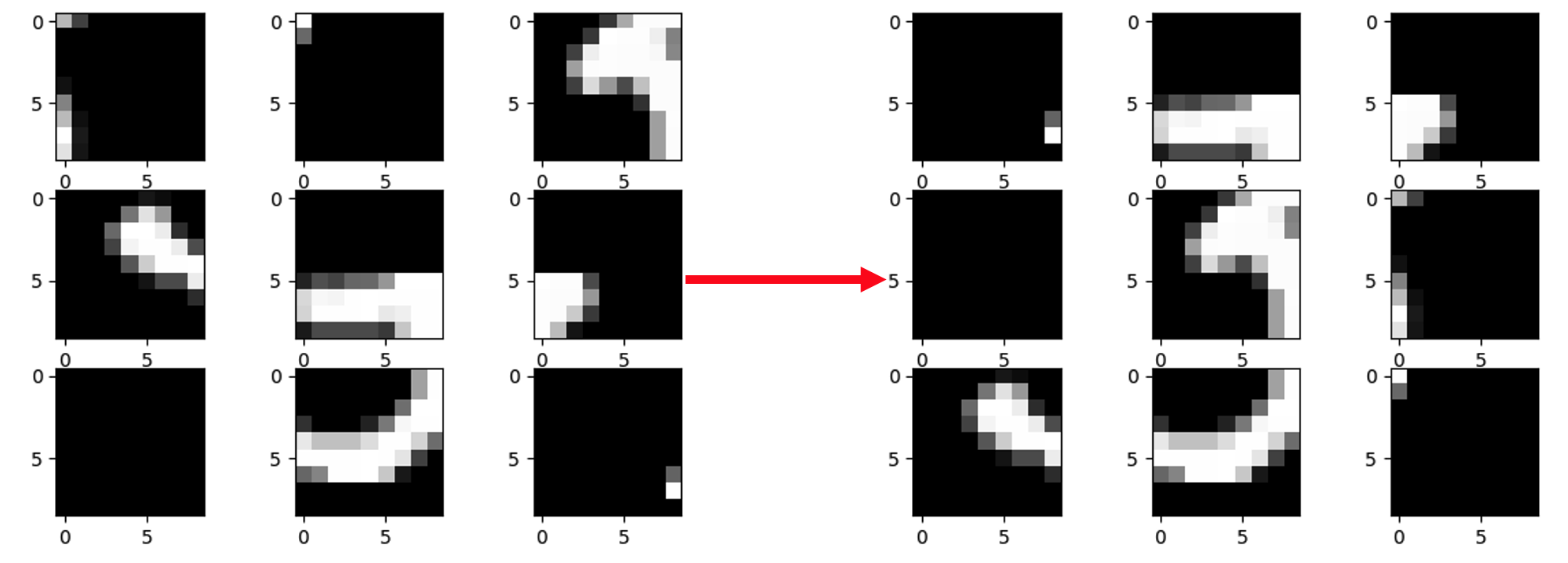
Pretty challenging, eh?
Specifically, we took MNIST images and created 3x3 jigsaw puzzles out of them. We framed this jigsaw game as a sequential swapping game, where each move involved swapping one piece with another. The goal of our algorithm was to reassemble the digit in the least number of swaps (correctness and efficiency).
Architecture and Approach
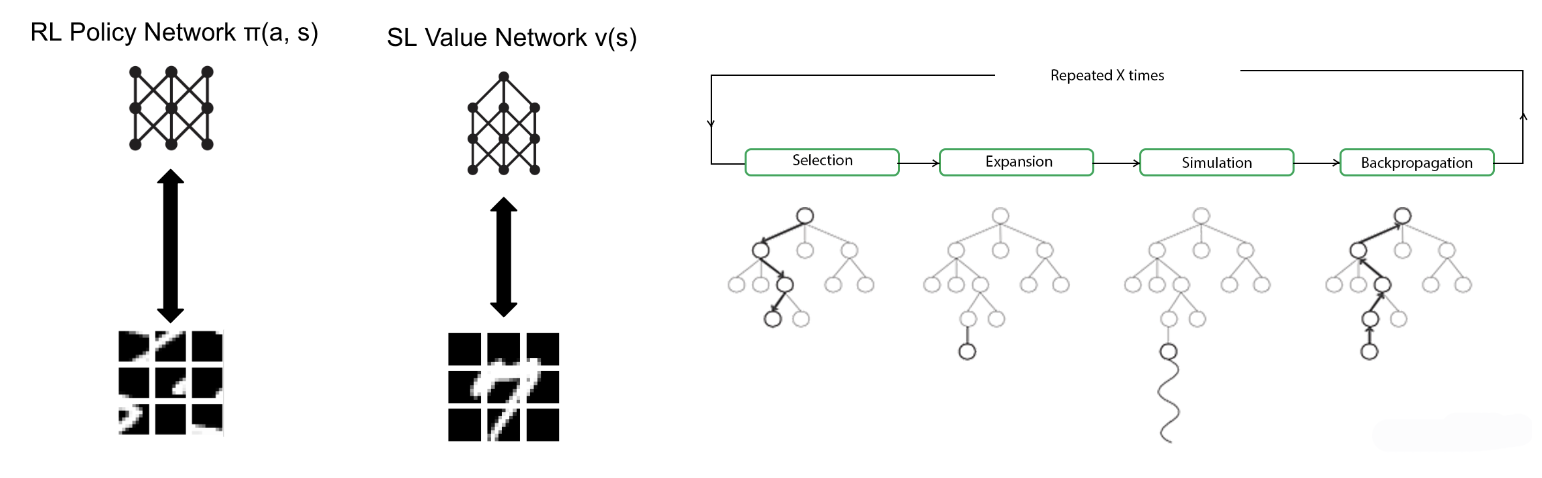
We were loosely inspired by AlphaZero (Silver et al. 2016), though we made significant modifications for our specific game and did not use self-play.
We trained a value network using supervised learning. The network took in a jigsaw puzzle (perhaps partially reassembled), and it outputted a scalar from 0 to 1 describing how close the puzzle was to being fully reassembled.
We trained a policy network using reinforcement learning. The network took in a jigsaw puzzle (perhaps partially reassembled), and it outputted a set of action-probability pairs.
Then, we performed Monte Carlo tree search (MCTS) that utilized the value network and the policy network to perform depth reduction and breadth reduction. The guiding principle is that the space of all possible sequences of swaps is too large to be searched efficiently, so we use deep learning to perform a more intelligent search.
Results
Our results were mixed, though I think our overall approach was successful.
We found that the value network alone, when used greedily, was able to solve the jigsaw puzzles around 90% of the time. However, context is needed. We asked the value network to generate swaps sequentially, and we would terminate after the model had managed to correctly swap the pieces into their intended positions. In particular, if a piece had only black pixels, we didn’t care where the algorithm placed it, as long as it was in one of spots that should only have black pixels.
When we combined the value network with the policy network in MCTS, the new algorithm solved puzzles around only half the time, though it was able to solve puzzles with far fewer swaps than the value network alone; often the the tree search would find a solution using a minimal number of swaps. Importantly, the tree search algorithm was given a more difficult task. We didn’t tell the tree search algorithm when to stop; it had to decide when it had found a solution. I believe this was the root cause of the lower success rate. When the tree search didn’t get stuck, it was able to solve the puzzles with fewer swaps than the value network alone.
With more time and hyperparameter tuning, we believe that we could have improved the performance of our algorithm. Our tree search algorithm had to weigh the value network and the policy network, and we had to choose a threshold for when to stop the search. We believe that we could have improved our algorithm by tuning these parameters.